Exploring INC’s 5000 Fastest Growing Companies of 2018
Every year, thousands of companies submit their 3 most recent years of financial information to Inc. magazine/website in the hopes of making it on their Inc. 5000 list of fastest growing private companies in America. In a previous post, I provided a script I put together to extract this data from https://www.inc.com/inc5000/list/2018. In this post, I explore the data and discover some interesting things along with some outliers and mistakes.
I discovered what seems to be some innacuracies in what was published. More specifically, there are several companies with 0 employees reported. There’s another company with $2.3 million in annual revenue and 100,000 employees, which can’t be right.
There are a few interesting plots in this post as well. Enjoy!
#import modules
import pandas as pd
import sqlite3
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
#connect to the database and create a dataframe out of the data in the database
conn = sqlite3.connect("inc2018.db")
df = pd.read_sql_query("SELECT * FROM company;", conn)
Top 5 Fastest Growing Private Companies
df.head()
| index | Rank | CompanyName | Leadership | 2017Revenue | Industry | Founded | Growth | Location | Employees | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | #1 | SwanLeap | Brad Hollister | $99 M | Logistics & Transportation | 2013 | 75,661% | Madison, WI | 49 |
| 1 | 1 | #2 | PopSockets | David Barnett | $168.8 M | Consumer Products & Services | 2010 | 71,424% | Boulder, CO | 118 |
| 2 | 2 | #3 | Home Chef | Patrick Vihtelic | $255 M | Food & Beverage | 2013 | 60,166% | Chicago, IL | 865 |
| 3 | 3 | #4 | Velocity Global | Ben Wright | $49.2 M | Business Products & Services | 2013 | 39,817% | Denver, CO | 78 |
| 4 | 4 | #5 | DEPCOM Power | Jim Lamon | $219.6 M | Energy | 2013 | 38,963% | Scottsdale, AZ | 104 |
Preparing the data for analysis
For any attribute in which the script is not able to find the html tag it is looking for, the script outputs “couldn’t find”. Below I will look for all rows that contain “couldn’t find” in any of the fields.
cant_find = df[df.apply(lambda row: row.astype(str).str.contains("couldn't find").any(), axis=1)]
cant_find
| index | Rank | CompanyName | Leadership | 2017Revenue | Industry | Founded | Growth | Location | Employees | |
|---|---|---|---|---|---|---|---|---|---|---|
| 71 | 71 | couldn't find | ConvertKit | Nathan Barry, 27 | couldn't find | Software | 2013 | couldn't find | Boise, ID | 30 |
| 267 | 267 | couldn't find | Stukent | Stuart Draper | couldn't find | Education | 2013 | couldn't find | Idaho Falls, ID | 48 |
| 414 | 414 | couldn't find | Lync America | Cynthia Lee | couldn't find | Logistics & Transportation | 2014 | couldn't find | Chattanooga, TN | 27 |
| 997 | 997 | couldn't find | Proximity Learning Inc. | Evan Erdberg | couldn't find | Education | 2009 | couldn't find | Austin, TX | 150 |
| 1339 | 1339 | couldn't find | 404 Page Not Found | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find |
| 1569 | 1569 | couldn't find | pNeo | Peter Wenham | couldn't find | Consumer Products & Services | 2008 | couldn't find | Denton, TX | 15 |
| 1693 | 1693 | couldn't find | KingPay | Ron Singh | couldn't find | Financial Services | 2013 | couldn't find | London , United Kingdom | 50 |
| 2251 | 2251 | couldn't find | 404 Page Not Found | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find |
| 2351 | 2351 | couldn't find | Greenback Tax Services | Carrie McKeegan | couldn't find | Financial Services | 2008 | couldn't find | Mong Kok, Hong Kong | 50 |
| 2485 | 2485 | couldn't find | EvoText | Johanna Wetmore | couldn't find | Software | 2014 | couldn't find | Burlington, MA | Small (25 - 49) |
| 2582 | 2582 | couldn't find | ITinspired | Robert Wise | $147.3 M | IT Services | 2011 | 151% | Baton Rouge, LA | Micro (10 - 24) |
| 2791 | 2791 | couldn't find | Nationwide Transport Services, LLC | Jason Foltz | couldn't find | Logistics & Transportation | 2009 | couldn't find | Fort Lauderdale, FL | 20 |
| 2857 | 2857 | couldn't find | Beehive Plumbing | Matthew Naylor | couldn't find | Construction | 1999 | couldn't find | West Jordan, UT | 24 |
| 4364 | 4364 | #3854 | Surface Mount Technology | couldn't find | $14.3 M | Manufacturing | 1997 | 68% | Appleton, WI | 130 |
| 4660 | 4660 | couldn't find | 404 Page Not Found | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find | couldn't find |
| 4971 | 4971 | couldn't find | Insight Global | Bert Bean | $1928.8 M | Business Products & Services | 2001 | 58% | Atlanta, GA | 2570 |
There are 16 company profiles for which the script was not able to extract at least one of the fields.
The reason that the script was not able to find some of the data is because of inconsistencies in the tags used to identify attribute types in the company profiles. For example, in the image below, you can see that revenue is presented in multiple ways.
Also, it appears the script may have ran into some broken links, indicated by the rows with “404 Page Not Found” in the CompanyName field.
Fortunately, the script was able to capture all the data for all but 16 companies. In order to make sure the script is able to collect all the information, I would have to account for these inconsistencies. For now, I will create a new dataframe with these removed from the data set.
df2 = df.drop(cant_find.index, axis = 0)
To view the data type of each field
df2.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4983 entries, 0 to 4998
Data columns (total 10 columns):
index 4983 non-null int64
Rank 4983 non-null object
CompanyName 4983 non-null object
Leadership 4983 non-null object
2017Revenue 4983 non-null object
Industry 4983 non-null object
Founded 4983 non-null object
Growth 4983 non-null object
Location 4983 non-null object
Employees 4983 non-null object
dtypes: int64(1), object(9)
memory usage: 428.2+ KB
We need to convert some of the attributes to numeric data types. These attributes are ‘2017Revenue’, ‘Growth’, ‘Founded’, and ‘Employees’.
df2["Revenue"] = pd.to_numeric(df2["2017Revenue"].apply(lambda x: 0 if x == "couldn't find" else x[1:-2]))
df2["Founded"] = pd.to_datetime(df2["Founded"].apply(lambda x: 0 if x == "couldn't find" else x)).dt.year
df2["GrowthPercent"] = pd.to_numeric(df2.Growth.apply(lambda x: 0 if x == "couldn't find" else x[:-1].replace(',', '')))
Some of the values in the ‘Employees’ attribute are provided as a range, which you can see below.
df2.iloc[[8]]
| index | Rank | CompanyName | Leadership | 2017Revenue | Industry | Founded | Growth | Location | Employees | Revenue | GrowthPercent | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 8 | #8 | Flexport | Ryan Petersen | $224.7 M | Logistics & Transportation | 2013 | 15,911% | San Francisco, CA | Large (250 - 499) | 224.7 | 15911 |
In order to convert the ‘Employees’ attribute to numeric, I will extract the upper number provided in the range for these types of values. To extract the upper value in the Employee counts provided as a range.
def dash(s):
if s.find("-") != -1:
return s[s.find("- ") + 2:-1]
else:
return s
df2["EmployeeUpdate"] = df2.Employees.apply(dash)
df2["EmployeeUpdate"] = pd.to_numeric(df2.EmployeeUpdate.apply(lambda x: 0 if x == "couldn't find" else x))
Looking at the data types of each field after the above operations.
df2.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4983 entries, 0 to 4998
Data columns (total 13 columns):
index 4983 non-null int64
Rank 4983 non-null object
CompanyName 4983 non-null object
Leadership 4983 non-null object
2017Revenue 4983 non-null object
Industry 4983 non-null object
Founded 4983 non-null int64
Growth 4983 non-null object
Location 4983 non-null object
Employees 4983 non-null object
Revenue 4983 non-null float64
GrowthPercent 4983 non-null int64
EmployeeUpdate 4983 non-null int64
dtypes: float64(1), int64(4), object(8)
memory usage: 545.0+ KB
Plots
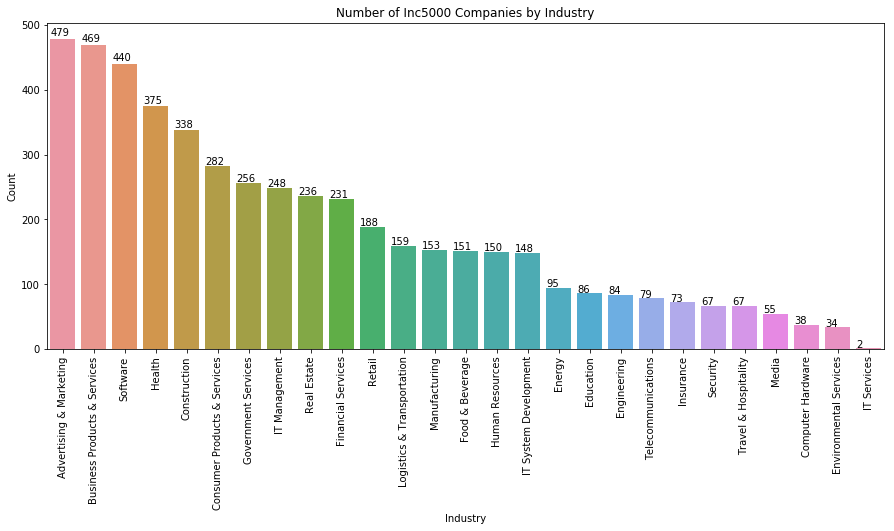
Number of Companies by Industry
a4_dims = (15, 6)
fig, ax = plt.subplots(figsize=a4_dims)
sns.countplot(df2.Industry, ax = ax, order= df2.Industry.value_counts().index)
plt.xticks(rotation=90)
plt.ylabel("Count")
plt.title("Number of Inc5000 Companies by Industry")
for p in ax.patches:
ax.annotate(str(p.get_height()), (p.get_x() * 1.0, p.get_height() * 1.01))
Number of Companies per City (top 30)
ax = df2.Location.value_counts().sort_values(ascending=False).head(30).plot.bar(figsize=a4_dims, title="2018 Inc5000 Companies Per City for Top 30 Cities")
for p in ax.patches:
ax.annotate(str(p.get_height()), (p.get_x() * 1.0, p.get_height() * 1.01))

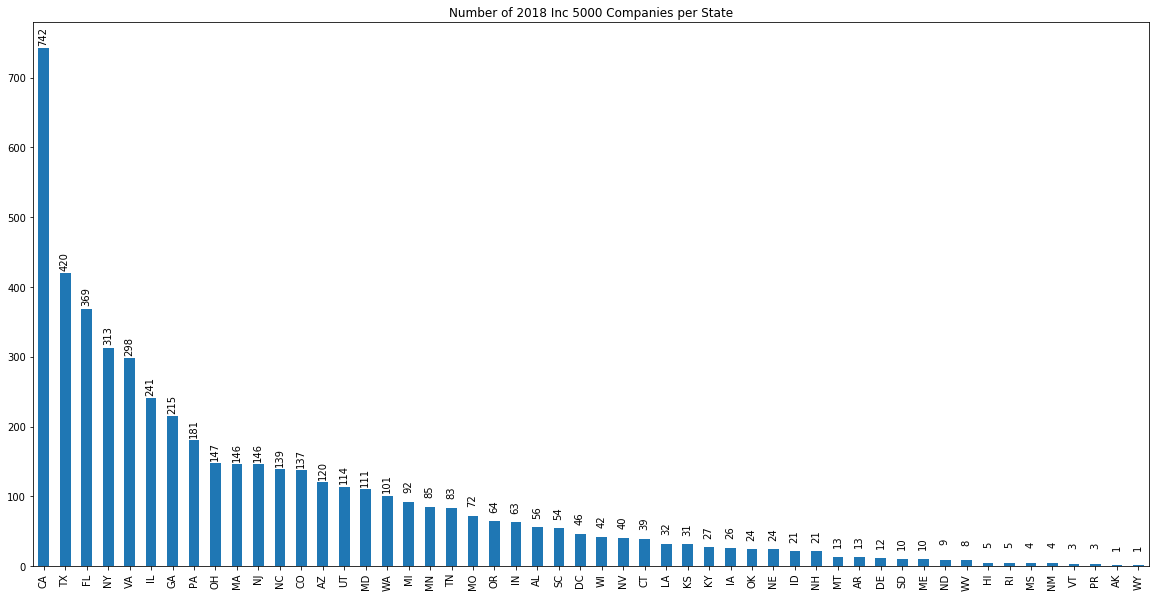
Number of Companies per State
# Have to create a "State" attribute by extracting the last two characters of the "Location" attribute
df2['State'] = df2["Location"].apply(lambda x: x[-2:])
aa = df2.State.value_counts().plot.bar(figsize=(20,10), title = "Number of 2018 Inc 5000 Companies per State")
for p in aa.patches:
aa.annotate(str(p.get_height()), (p.get_x() * 1.0, p.get_height() + 20), rotation=90)
Growth Versus Revenue Scatterplot
a4_dims = (20, 10)
fig, ax = plt.subplots(figsize=a4_dims)
sns.scatterplot(x="EmployeeUpdate", y="Revenue", data=df2, ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x22e1a5a82e8>

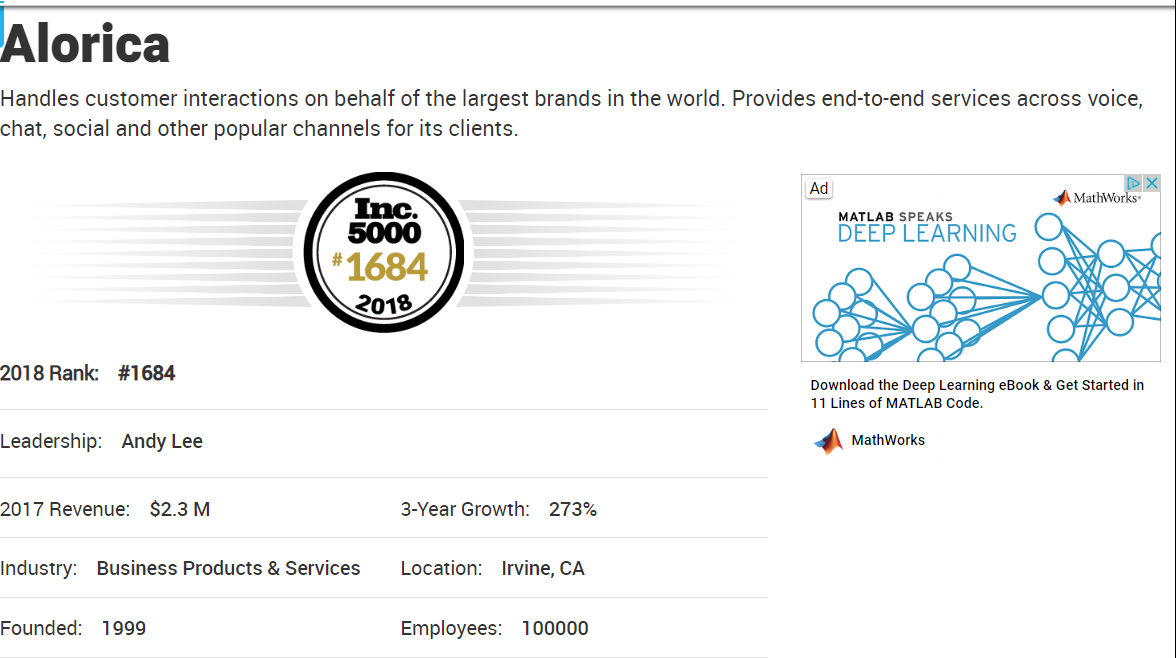
There are a few companies that look like outliers. There is one in particular that stands out a lot. The point with about 100,000 employees but close to 0 revenue. Let’s take a look at this one.
df2[(df2.EmployeeUpdate > 90000) & (df2.EmployeeUpdate < 110000)]
| index | Rank | CompanyName | Leadership | 2017Revenue | Industry | Founded | Growth | Location | Employees | Revenue | GrowthPercent | EmployeeUpdate | State | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1682 | 1682 | #1684 | Alorica | Andy Lee | $2.3 M | Business Products & Services | 1999 | 273% | Irvine, CA | 100000 | 2.3 | 273 | 100000 | CA |
Alcoria has 100,000 employees but only $2.3M in revenue. This doesn’t seem right. However, as you can see in the image below, that is exactly what is provided in their Inc.com profile.
Some companies have a value of zero employees in their profile.
df2[df2.Employees == '0']
| index | Rank | CompanyName | Leadership | 2017Revenue | Industry | Founded | Growth | Location | Employees | Revenue | GrowthPercent | EmployeeUpdate | State | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1973 | 1973 | #1975 | MJ Freeway | Amy Poinsett | $8.1 M | Software | 2010 | 226% | Denver, CO | 0 | 8.1 | 226 | 0 | CO |
| 2267 | 2267 | #2270 | Playags | David Lopez | $212 M | Business Products & Services | 2005 | 194% | Las Vegas, NV | 0 | 212.0 | 194 | 0 | NV |
| 2899 | 2899 | #2902 | Grand Power Systems | Stephen Paul | $29.5 M | Energy | 1948 | 141% | Grand Haven, MI | 0 | 29.5 | 141 | 0 | MI |
| 3158 | 3158 | #3161 | BayCom | George Guarini | $44.3 M | Financial Services | 2004 | 125% | Walnut Creek, CA | 0 | 44.3 | 125 | 0 | CA |
| 3434 | 3434 | #3437 | Peddle | Tim Yarosh | $65.6 M | Consumer Products & Services | 2011 | 111% | Austin, TX | 0 | 65.6 | 111 | 0 | TX |
| 3435 | 3435 | #3438 | E-file.com | Aaron Rosenthal and Robert Reynard | $5.1 M | Consumer Products & Services | 2011 | 111% | Ponte Vedra, FL | 0 | 5.1 | 111 | 0 | FL |
| 4066 | 4066 | #4069 | Bridgewater Bancshares | Jerry Baack | $52.5 M | Financial Services | 2005 | 86% | Bloomington, MN | 0 | 52.5 | 86 | 0 | MN |
| 4776 | 4776 | #4778 | Ellison Bakery | Todd Wallin | $29.9 M | Food & Beverage | 1945 | 64% | Ft. Wayne, IN | 0 | 29.9 | 64 | 0 | IN |
| 4822 | 4822 | #4824 | Quality Aluminum Products | Bob Clark | $45 M | Manufacturing | 1990 | 63% | Hastings, MI | 0 | 45.0 | 63 | 0 | MI |
| 4951 | 4951 | #4953 | Custom Profile | John Boeschenstein | $48.3 M | Manufacturing | 1992 | 59% | Grand Rapids, MI | 0 | 48.3 | 59 | 0 | MI |
| 4977 | 4977 | #4979 | Mediassociates | Scott Brunjes | $11.5 M | Advertising & Marketing | 1996 | 58% | Sandy Hook, CT | 0 | 11.5 | 58 | 0 | CT |
The image below confirms that the script pulled the data as is provided in the profile.

Creating a new dataframe for companies with greater than zero employees
df3 = df2[df2.EmployeeUpdate > 0]
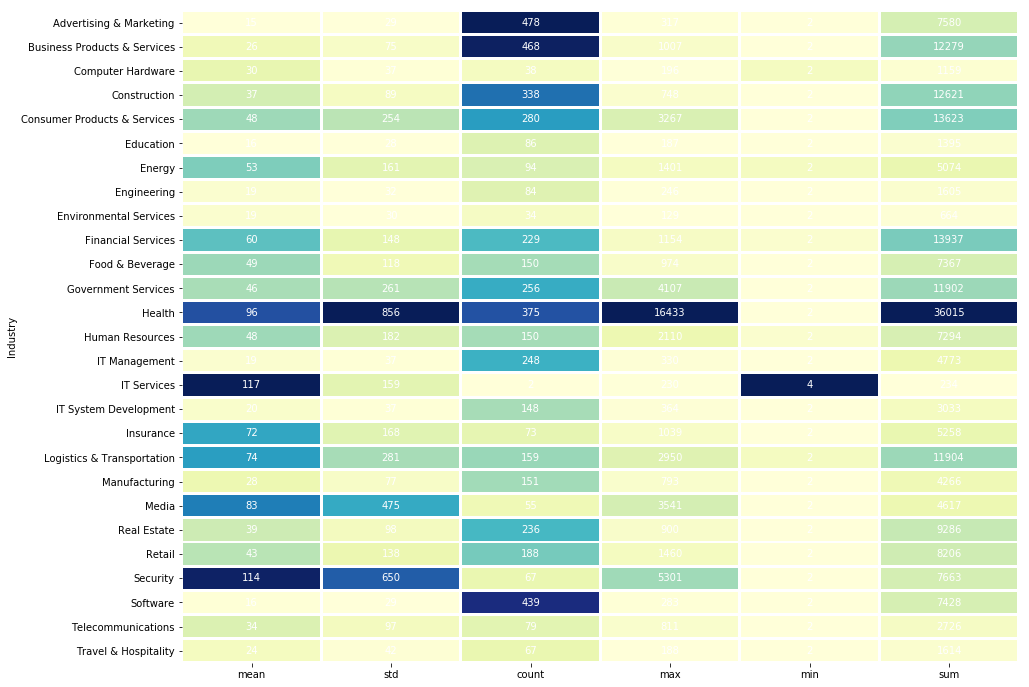
Comparing Statistics by Industry
A traditional heatmap must have the same unit of measurement in every cell. Below is a function that accepts a pandas grouped by object and creates a heatmap where each column in the heatmap is based on its own unique scale. This gives us the visual benefit of a heatmap while also allowing us to compare the different industries along different statistical dimensions.
def groupedHeatMap(groupedObject, cmap = "YlGnBu", title = ''):
import shutil
index_values = groupedObject.index.values
a5_dims = (15, 12)
fig, ax =plt.subplots(1,len(groupedObject.columns), figsize=a5_dims)
for i in np.arange(len(groupedObject.columns)):
stat = groupedObject[groupedObject.columns[i]].sort_index()
if i == 0:
sns.heatmap(stat.to_frame(),ax=ax[0], cbar=False, cmap=cmap, linewidths=2)
for j in range(len(index_values)):
text = ax[0].text(.5,j+.5, str(int(stat.iloc[j])), ha="center", va="center", color="w")
else:
sns.heatmap(stat.to_frame(),ax=ax[i], cbar=False, cmap=cmap, linewidths=2)
ax[i].set_yticklabels(ax[i].get_yticklabels(), fontsize=0)
ax[i].set_ylabel("")
ax[i].yaxis.set_visible(False)
for j in range(len(index_values)):
text = ax[i].text(.5,j+.5, str(int(stat.iloc[j])), ha="center", va="center", color="w")
plt.subplots_adjust(wspace = .001)
columns = shutil.get_terminal_size().columns
print(title.center(columns))
fig.show()
Using the newly created function
rev_stats = df3[df3.Revenue > 0].groupby("Industry").agg(['mean', 'std', 'count', 'max', 'min', 'sum']).Revenue
groupedHeatMap(rev_stats, title="Revenue Statistics by Industry (In Millions)")